
02-04-2022 17:54:25
[Data Analytics] Analyse python Population francaise
Et si quelqu'un a la raison pour laquelle les 2 personnes de 144ans n'ont jamais été identifiées comme les plus vieilles du monde, je suis preneur :)
Have fun.
02-04-2022 17:33:43
Configuration Reverse Proxy pour Streamlit
Streamlit intégrant un serveur web dédié, il nécessite un port propre à lui. Il peut donc etre pratique de le mettre derrière un Reverse Proxy pour y accéder sur le port 80 ou 443.
Ayant un peu bataillé car il faut le mettre en place pour les requete HTTP mais également les Websocket, je partage donc une conf opérationnelle
Coté Apache, on va activer les mods suivants :
a2enmod proxy proxy_http proxy_wstunnel
Ensuite on va créer un fichier /etc/apache2/sites-available/proxy_perso.conf contenant notre conf
<VirtualHost *:80>
ServerName ml.madpowah.org
ServerAdmin admin@mail.com
ErrorLog ${APACHE_LOG_DIR}/error-streamlit.log
CustomLog ${APACHE_LOG_DIR}/access-streamlit.log combined
ProxyPreserveHost On
ProxyRequests Off
<Proxy *>
order deny,allow
Allow from all
</Proxy>
ProxyPass / "http://127.0.0.1:8501/"
ProxypassReverse / "http://127.0.0.1:8501/"
<Location "/stream">
ProxyPass ws://127.0.0.1:8501/stream
ProxyPassReverse ws://127.0.0.1:8501/stream
</Location>
</VirtualHost>
On redémarre Apache et si on n'a pas de retour c'est que c'est bon.
systemctl restart apache2
J'en profite pour mettre du coup l'adresse pour quelques démo de ML avec streamlit.
Have Fun !
02-06-2020 22:48:53
Streamlit Framework Python pour DataScience
Streamlit est un framework python offrant des outils permettant d'afficher via un serveur web ses graphiques ainsi que les résultats des dataframes. Il permet d'afficher directement via la lib matplotlib mais possède également ses propres librairie permettant de créer rapidement des boutons, graphiques en tous genres.
Pour ma part j'ai donc mis en page mes tests de code pour le suivi du Covid-19 sur la page http://ml.madpowah.org. Vous y trouverez :
- Suivi du Covid-19 en France
- Evolution nombre de cas / guéris / décès
- Evolution quotidienne filtré via un filtre gaussien pour lisser le tout
- Evolution par age / sexe
- Hospitalisations / Réanimations
- Suivi dans le monde avec choix du pays
- Démonstration d'un système prédictif en Time séries avec modèle ARIMA
- Démo d'un Sentiment Analysis sur des termes #covid #stopcovid analysé sur twitter via tweepy. La base des avis a été créée par mes soins et stockée via MongoDB
- Page de test du moteur de Sentiment Analysis (TFIDF + Naive Bayésienne)
Il me reste pas mal de choses à tester dans ce domaine donc sujet à suivre !
03-05-2020 00:38:35
Exemple de Data Science sur Covid-19 et Predictions
Je préviens avant, je ne suis ni épidémiologiste ou quoi que ce soit donc ce que je dis n'engage que moi et j'interprete selon mes pensées.
Tout d'abord nous allons commencer par utiliser les données mises à disposition par le gouvernement. .
Analyse globale
Commencons par regarder globalement l'évolution des personnes hospitalisées pour Covid. Pour cela on va charger notre fichier CSV avec la librairie Pandas puis utiliser Seaborn
pour mettre tout ca en graphique.
import matplotlib.pyplot as plt
import pandas as pd
pd.plotting.register_matplotlib_converters()
import seaborn as sns
# Fichier de data sur data.gouv.fr
file = "sursaud-covid19-quotidien-2020-04-30-19h00-France.csv"
# On va utiliser Pandas pour traiter ca et on va selectionner de maniere differenciee chaque age (y a plus propre mais c'est plus lisible je trouve)
txt = pd.read_csv(file)
# On choisi tous les cas quels que soit leur age
data = txt[txt['sursaud_cl_age_corona'] == '0']
# On va reduire l'index de chaque en divisant par 6 vu qu'il y a une donnee toute les 6 lignes
data.index = data.index.map(lambda x: int(x / 6))
plt.figure(figsize=(24, 10))
# Vous pouvez commentez le moins visuel des 2 selon vos gouts
sns.barplot(x=data.index, y=data['nbre_hospit_corona'], label="Nb hospit corona")
sns.lineplot(data=data['nbre_hospit_corona'], label="Nb hospit corona")
plt.xlabel('Nb jour')
plt.show()
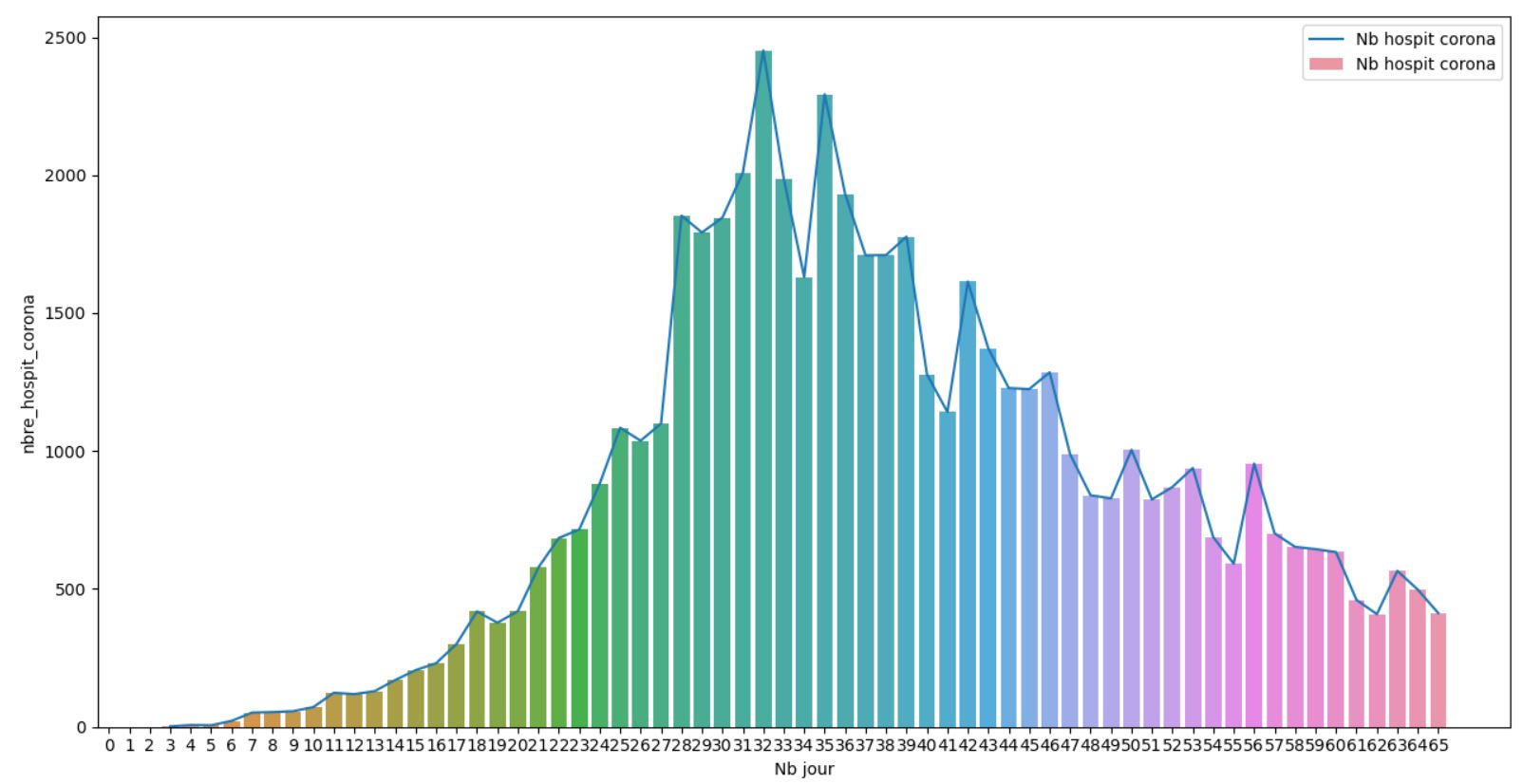
Le confinement a débuté le 14 Mars, ce qui correspond au jour 19 ici. On voit que le pic est arrivé Jour 32, donc le 27 Mars ce qui semble cohérent au 6 / 7 jour d'incubation avant les 1ers symptomes puis ici des aggravations entrainant le pic. On voit bien que cette phase de courbe est exponentielle et qu'attendre plus aurait explosé le système hospitalier. On voit ici qu'il a été efficace car pas de butée sur plusieurs jours à un meme niveau.
On observe une décroissance des hospitalisations qui semble un peu ralentir mais on se rapproche de la limite basse qui va etre compliquée à réduire sans nouvelle mesure sanitaire sachant que la fin du confinement approche.
Analyse par age
Regardons maintenant cette courbe mais par age. Les données fournies nous permettent d'analyser 5 tranches d'ages :
- les moins de 15ans
- de 15 à 44ans
- de 45 à 64ans
- de 65 à 74ans
- + de 74ans
import matplotlib.pyplot as plt
import pandas as pd
pd.plotting.register_matplotlib_converters()
import seaborn as sns
# Fichier de data sur data.gouv.fr
file = "sursaud-covid19-quotidien-2020-04-30-19h00-France.csv"
# On va utiliser Pandas pour traiter ca et on va selectionner de maniere differenciee chaque age (y a plus propre mais c'est plus lisible je trouve)
txt = pd.read_csv(file)
data = txt[txt['sursaud_cl_age_corona'] == '0']
data15 = txt[txt['sursaud_cl_age_corona'] == 'A']
data44 = txt[txt['sursaud_cl_age_corona'] == 'B']
data64 = txt[txt['sursaud_cl_age_corona'] == 'C']
data74 = txt[txt['sursaud_cl_age_corona'] == 'D']
data99 = txt[txt['sursaud_cl_age_corona'] == 'E']
# On va reduire l'index de chaque en divisant par 6 vu qu'il y a une donnee toute les 6 lignes
data.index = data.index.map(lambda x: int(x / 6))
data15.index = data15.index.map(lambda x: int(x / 6))
data44.index = data44.index.map(lambda x: int(x / 6))
data64.index = data64.index.map(lambda x: int(x / 6))
data74.index = data74.index.map(lambda x: int(x / 6))
data99.index = data99.index.map(lambda x: int(x / 6))
plt.figure(figsize=(24, 10))
# Evolution des hospitalisations pour COVID par age
# sns.lineplot(data=data, x=data.index, y=data['nbre_hospit_corona'], hue='sursaud_cl_age_corona', label=["Nb hospitalisation corona"]) # Fait tout en 1 ligne mais reste a voir les labels
sns.lineplot(data=data['nbre_hospit_corona'], label="Nb hospitalisation corona")
sns.lineplot(data=data15['nbre_hospit_corona'], label="Nb hospitalisation corona - 15ans")
sns.lineplot(data=data44['nbre_hospit_corona'], label="Nb hospitalisation corona 15 - 44ans")
sns.lineplot(data=data64['nbre_hospit_corona'], label="Nb hospitalisation corona 45 - 64ans")
sns.lineplot(data=data74['nbre_hospit_corona'], label="Nb hospitalisation corona 65 - 74ans")
sns.lineplot(data=data99['nbre_hospit_corona'], label="Nb hospitalisation corona + 74ans")
plt.xlabel('Date')
plt.show()
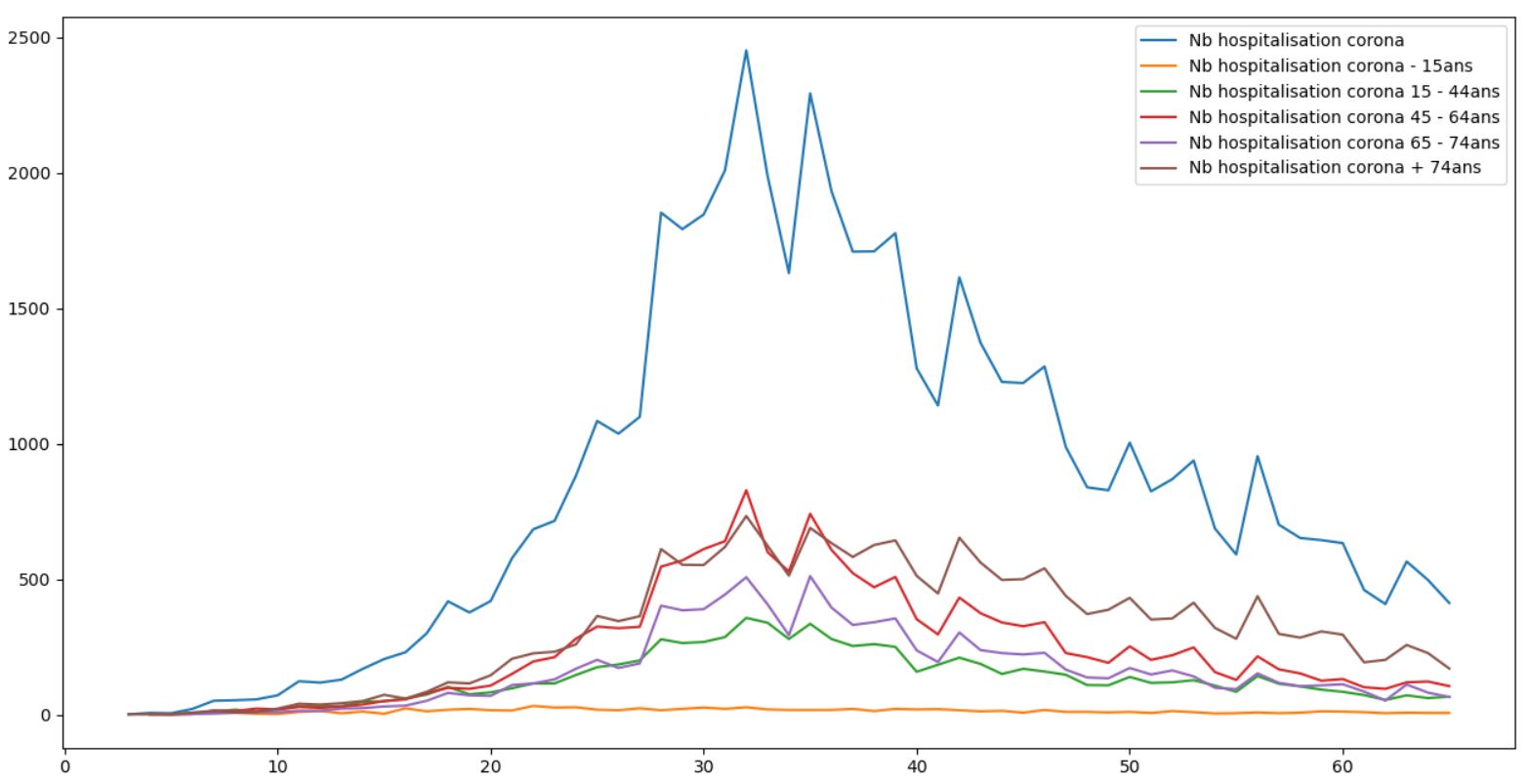
Ici on voit bien que les cas de jeunes est très faible. Pour le reste, à partir de 15ans je reste moins catégorique. L'age ne semble pas vraiment impacter le taux d'hospitalisation.
Celui-ci semble plus lié à un facteur autre, telle une comorbidité qui peut etre diverse selon l'age. Bien sur cela est vrai pour la tranche 15-74ans. Après on voit quand meme bien que cette population est bien plus atteinte et fragile.
On entend très souvent que le Covid est une maladie qui impacte les plus agés. C'est peut etre vrai pour l'aspect léthal mais pour ce qui est de l'hospitalisation, je serai moins catégorique.
Analyse par sexe
Récupérons maintenant les données pour afficher toujours ce taux d'hospitalisation mais cette fois par sexe pour voir s'il y a une différence.
import matplotlib.pyplot as plt
import pandas as pd
pd.plotting.register_matplotlib_converters()
import seaborn as sns
# Fichier de data sur data.gouv.fr
file = "sursaud-covid19-quotidien-2020-04-30-19h00-France.csv"
# On va utiliser Pandas pour traiter ca et on va selectionner de maniere differenciee chaque age (y a plus propre mais c'est plus lisible je trouve)
txt = pd.read_csv(file)
data = txt[txt['sursaud_cl_age_corona'] == '0']
# On va reduire l'index de chaque en divisant par 6 vu qu'il y a une donnee toute les 6 lignes
data.index = data.index.map(lambda x: int(x / 6))
plt.figure(figsize=(24, 10))
# Evolution des hospitalisations pour COVID par sexe
sns.lineplot(data=data['nbre_hospit_corona'], label="Nb hospitalisation corona")
sns.lineplot(data=data['nbre_hospit_corona_h'], label="Nb hospitalisation corona homme")
sns.lineplot(data=data['nbre_hospit_corona_f'], label="Nb hospitalisation corona femme")
plt.xlabel('Date')
plt.show()
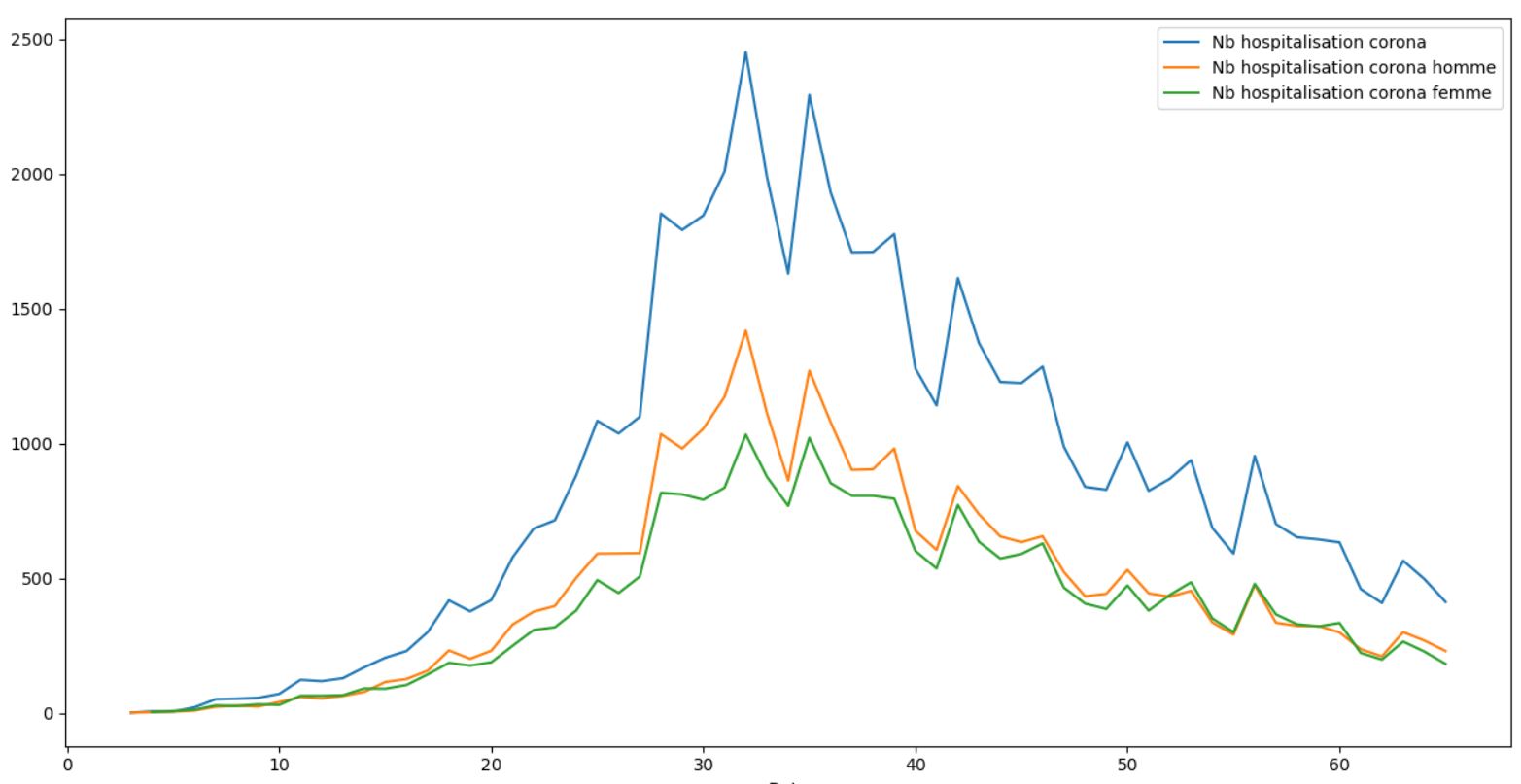
On observe principalement une différence au moment du pic. Une fois que celui-ci est passé, les courbes Hommes / Femmes finissent par s'entrecroiser régulièrement montrant qu'au final il n'y a pas vraiment de différence d'impact. Le pic préalable pourrait etre du au fait par exemple que les hommes ont tendance à avoir plus de contacts physiques avec le serrage de main ou autre. Une fois les gestes barrières et le confinement mis en place, cette différenciation disparait alors.
Analyse des taux de nouveaux cas / guéris et décès
Nous allons maintenant utiliser les données du CSSE de l'Universite de John Hopkins
afin de récupérer les données sur les nouveaux cas / guéris et décès en France et comparer cela avec la Corée du Sud pour tenter de prédire une date de fin de confinement.
Nous allons afficher cela via barplot() en stackant les 3 données.Pour cela on va concaténer les 3 dataframes puis créer une colonne qui va soustraire les décès et cas guéris aux cas détectés
afin d'avoir le nombre réel de cas actuel en France.
import matplotlib.pyplot as plt
import pandas as pd
pd.plotting.register_matplotlib_converters()
import seaborn as sns
import warnings # `do not disturbe` mode
warnings.filterwarnings('ignore')
fileconfirmed = "confirmed_global_29-04.csv"
filedeath = "deaths_global_29-04.csv"
filerecovered = "recovered_global_29-04.csv"
# On charge le fichier via Pandas
data = pd.read_csv(fileconfirmed)
# On recupere les donnees de la France
data['Province/State'] = data['Province/State'].fillna(0)
dataconfirmed = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
data = pd.read_csv(filedeath)
data['Province/State'] = data['Province/State'].fillna(0)
datadeaths = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
data = pd.read_csv(filerecovered)
data['Province/State'] = data['Province/State'].fillna(0)
datarecovered = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
# On supprime les colonnes qui ne nous servent pas
dataconfirmed = dataconfirmed.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
# On va inverser les colonnes et lignes pour pouvoir analyser ligne par ligne
dataconfirmed = pd.np.transpose(dataconfirmed)
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.rename(columns={cols[0]: 'Confirmed'})
# On refait de meme pour les deces et les gueris
datadeaths = datadeaths.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datadeaths = pd.np.transpose(datadeaths)
cols = datadeaths.columns
datadeaths = datadeaths.rename(columns={cols[0]: 'Deaths'})
datarecovered = datarecovered.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datarecovered = pd.np.transpose(datarecovered)
cols = datarecovered.columns
datarecovered = datarecovered.rename(columns={cols[0]: 'Recovered'})
# On concatene les Dataframes
datacomplete = pd.concat([dataconfirmed, datadeaths, datarecovered], axis=1, sort=False)
# On cree une colone au Dataframe de cas reels actuels
datacomplete['Restant'] = datacomplete['Confirmed'] - datacomplete['Recovered'] - datacomplete['Deaths']
# On n'affiche du 45e jour a la fin pour supprimer les 1ers jours quasi nuls
datacomplete = datacomplete[45:]
# On affiche cette fois en barplot()
sns.barplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Confirmed'], label="Nb confirme", color="blue")
sns.barplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Recovered'], label="Nb gueris", color="green")
sns.barplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Deaths'], label="Nb morts", color="black")
plt.xlabel('Date')
plt.show()
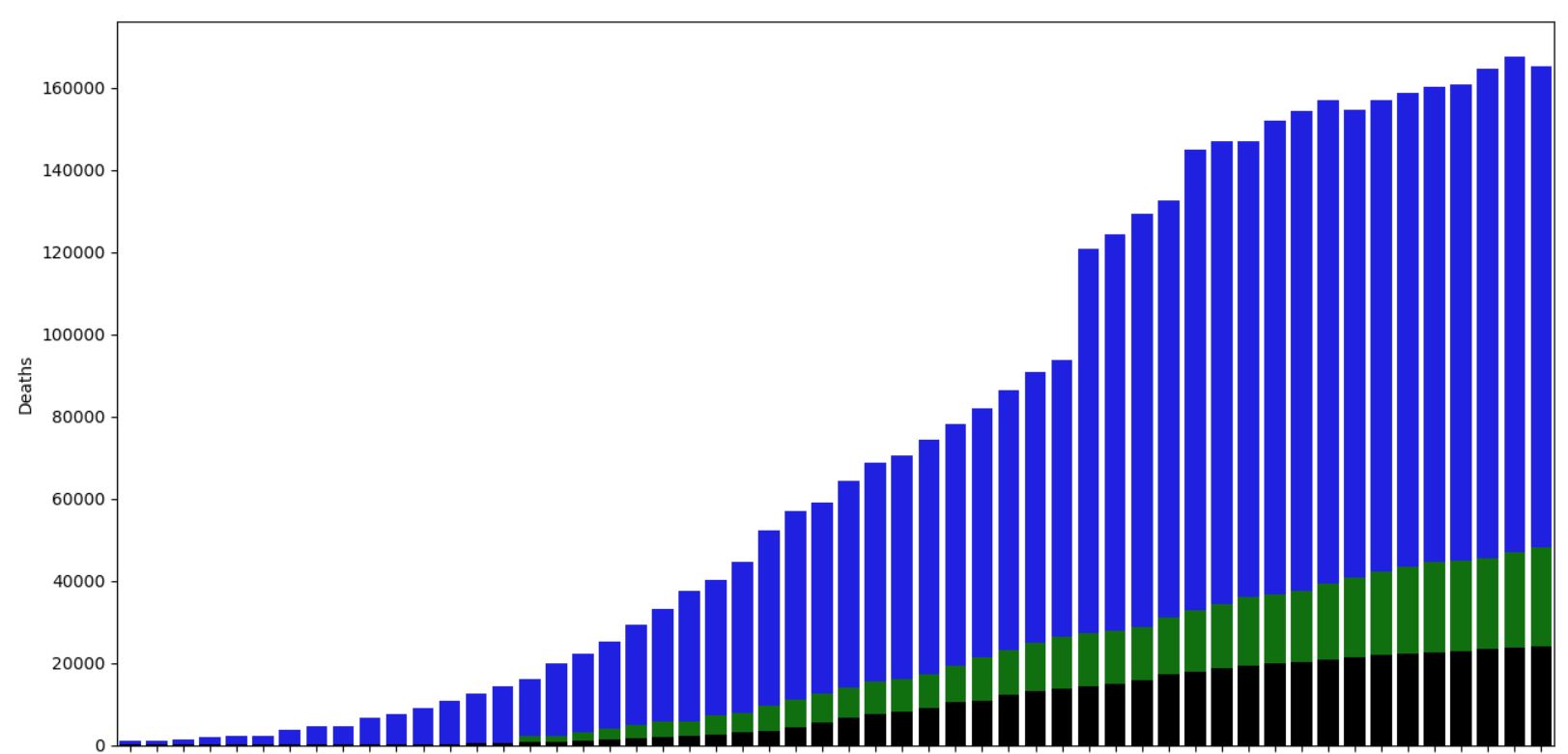
Rien à dire de particulier. La courbe des décès semble s'aplanir ce qui est bon signe. Celle des guéris légèrement aussi, mais en comparant avec la Corée du Sud, on constate que c'est pareil donc cela semble normal.
Nous allons ensuite afficher le nombre de cas réels actuels. Pour cela nous allons concaténer les 3 dataframes puis créer une colonne qui va soustraire les décès et cas guéris aux cas détectés
afin d'avoir le nombre réel de cas actuel en France.
import matplotlib.pyplot as plt
import pandas as pd
pd.plotting.register_matplotlib_converters()
import seaborn as sns
import warnings # `do not disturbe` mode
warnings.filterwarnings('ignore')
fileconfirmed = "confirmed_global_29-04.csv"
filedeath = "deaths_global_29-04.csv"
filerecovered = "recovered_global_29-04.csv"
# On charge le fichier via Pandas
data = pd.read_csv(fileconfirmed)
# On recupere les donnees de la France
data['Province/State'] = data['Province/State'].fillna(0)
dataconfirmed = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
data = pd.read_csv(filedeath)
data['Province/State'] = data['Province/State'].fillna(0)
datadeaths = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
data = pd.read_csv(filerecovered)
data['Province/State'] = data['Province/State'].fillna(0)
datarecovered = data[((data['Country/Region'] == 'France') & (data['Province/State'] == 0))]
# On supprime les colonnes qui ne nous servent pas
dataconfirmed = dataconfirmed.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
# On va inverser les colonnes et lignes pour pouvoir analyser ligne par ligne
dataconfirmed = pd.np.transpose(dataconfirmed)
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.rename(columns={cols[0]: 'Confirmed'})
# On refait de meme pour les deces et les guéris
datadeaths = datadeaths.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datadeaths = pd.np.transpose(datadeaths)
cols = datadeaths.columns
datadeaths = datadeaths.rename(columns={cols[0]: 'Deaths'})
datarecovered = datarecovered.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datarecovered = pd.np.transpose(datarecovered)
cols = datarecovered.columns
datarecovered = datarecovered.rename(columns={cols[0]: 'Recovered'})
# On concatene les Dataframes
datacomplete = pd.concat([dataconfirmed, datadeaths, datarecovered], axis=1, sort=False)
# On cree une colone au Dataframe de cas reels actuels
datacomplete['Restant'] = datacomplete['Confirmed'] - datacomplete['Recovered'] - datacomplete['Deaths']
# On n'affiche du 45e jour a la fin pour supprimer les 1ers jours quasi nuls
datacomplete = datacomplete[45:]
# On affiche cette fois en barplot() les cas reels
sns.barplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Restant'], label="Nb confirme", color="blue")
plt.xlabel('Date')
plt.show()
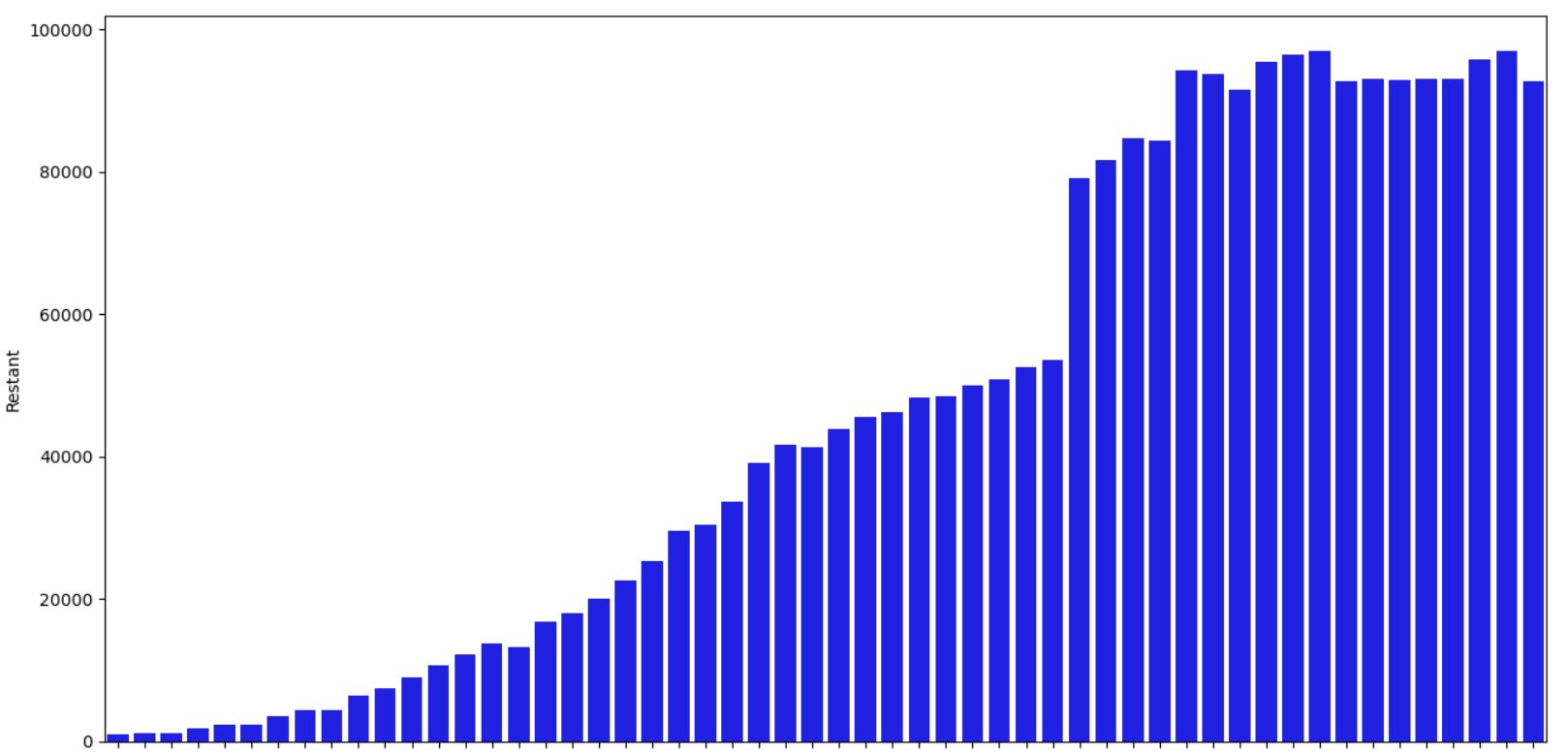
On constate que l'on est sur un plateau montrant une stabilisation de la situation mais pas encore un changement de tendance à la baisse, ce qui pourrait etre un critère évident avant d'envisager un déconfinement. Y a du mieux mais cela ne semble pas suffisant. Il reste 1 semaine pour donc retourner cette tendance.
Comparaison France / Corée du Sud
Pour imaginer le fonctionnement d'un modèle, le mieux reste d'en avoir un qui s'est déjà produit pour ensuite faire des prédictions sur l'actuel. Le Covid-19 est une maladie récente
et du coup pour comparer j'ai décidé arbitrairement de prendre la Corée du Sud. Certes la Corée n'a pas choisie notre méthode mais elle est sur une bonne dynamique de fin d'épidémie.
Pour information pour ceux qui n'ont pas suivi leur méthode, ils n'ont pas confiné mais ont imposé drastiquement la mise en place de gestes barrières comme les masques, de tester massivement
et de mettre en place un système via smartphone de suivi et tracabilité des malades pour détecter tous les cas à risque au plus vite.
Ici je décide donc d'afficher la France et la Corée du Sud en multipliant volontairement les données de la Corée pour avoir une taille visuelle à peu pret semblable à la France.
# -*- coding: utf-8 -*-
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings # `do not disturbe` mode
warnings.filterwarnings('ignore')
# Les DATA
fileconfirmed = "confirmed_global_29-04.csv"
filedeath = "deaths_global_29-04.csv"
filerecovered = "recovered_global_29-04.csv"
# On Cree le Dataframe en recuperant la France et la Coree du Sud qui servira de comparaison
data = pd.read_csv(fileconfirmed)
data['Province/State'] = data['Province/State'].fillna(0)
dataconfirmed = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
data = pd.read_csv(filedeath)
data['Province/State'] = data['Province/State'].fillna(0)
datadeaths = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
data = pd.read_csv(filerecovered)
data['Province/State'] = data['Province/State'].fillna(0)
datarecovered = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
# Au vu du format de la Time Serie, on va transformer les colonnes en ligne
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
dataconfirmed = pd.np.transpose(dataconfirmed)
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.rename(columns={cols[0]: 'Confirmed France', cols[1]: 'Confirmed Coree'})
datadeaths = datadeaths.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datadeaths = pd.np.transpose(datadeaths)
cols = datadeaths.columns
datadeaths = datadeaths.rename(columns={cols[0]: 'Deaths France', cols[1]: 'Deaths Coree'})
datarecovered = datarecovered.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datarecovered = pd.np.transpose(datarecovered)
cols = datarecovered.columns
datarecovered = datarecovered.rename(columns={cols[0]: 'Recovered France', cols[1]: 'Recovered Coree'})
# On concatène les Dataframe pour n'en faire qu'un
datacomplete = pd.concat([dataconfirmed, datadeaths, datarecovered], axis=1, sort=False)
# On cree une colone au Dataframe de cas reels actuels
datacomplete['Restant France'] = datacomplete['Confirmed France'] - datacomplete['Recovered France'] - datacomplete[
'Deaths France']
datacomplete['Restant Coree'] = datacomplete['Confirmed Coree'] - datacomplete['Recovered Coree'] - datacomplete[
'Deaths Coree']
# On va renommer les dates pour etre au format Pandas (pas utile ici mais vous saurez comment modifier les valeurs des lignes
def formatDate(row):
dates = row
datesplit = dates.split('/')
row = "2020-" + str(datesplit[0]) + "-" + str(datesplit[1])
return row
datacomplete.index.names = ['Date']
datacomplete = datacomplete.reset_index()
datacomplete['Date'] = datacomplete['Date'].apply(formatDate)
# On affiche les 2 courbes des pays, en bleu la France et en rouge la Coree
plt.figure(figsize=(24, 10))
sns.lineplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Restant France'], label="Nb confirme France",
color="blue")
sns.lineplot(data=datacomplete, x=datacomplete.index, y=datacomplete['Restant Coree'] * 12, label="Nb confirme Coree",
color="red")
plt.show()
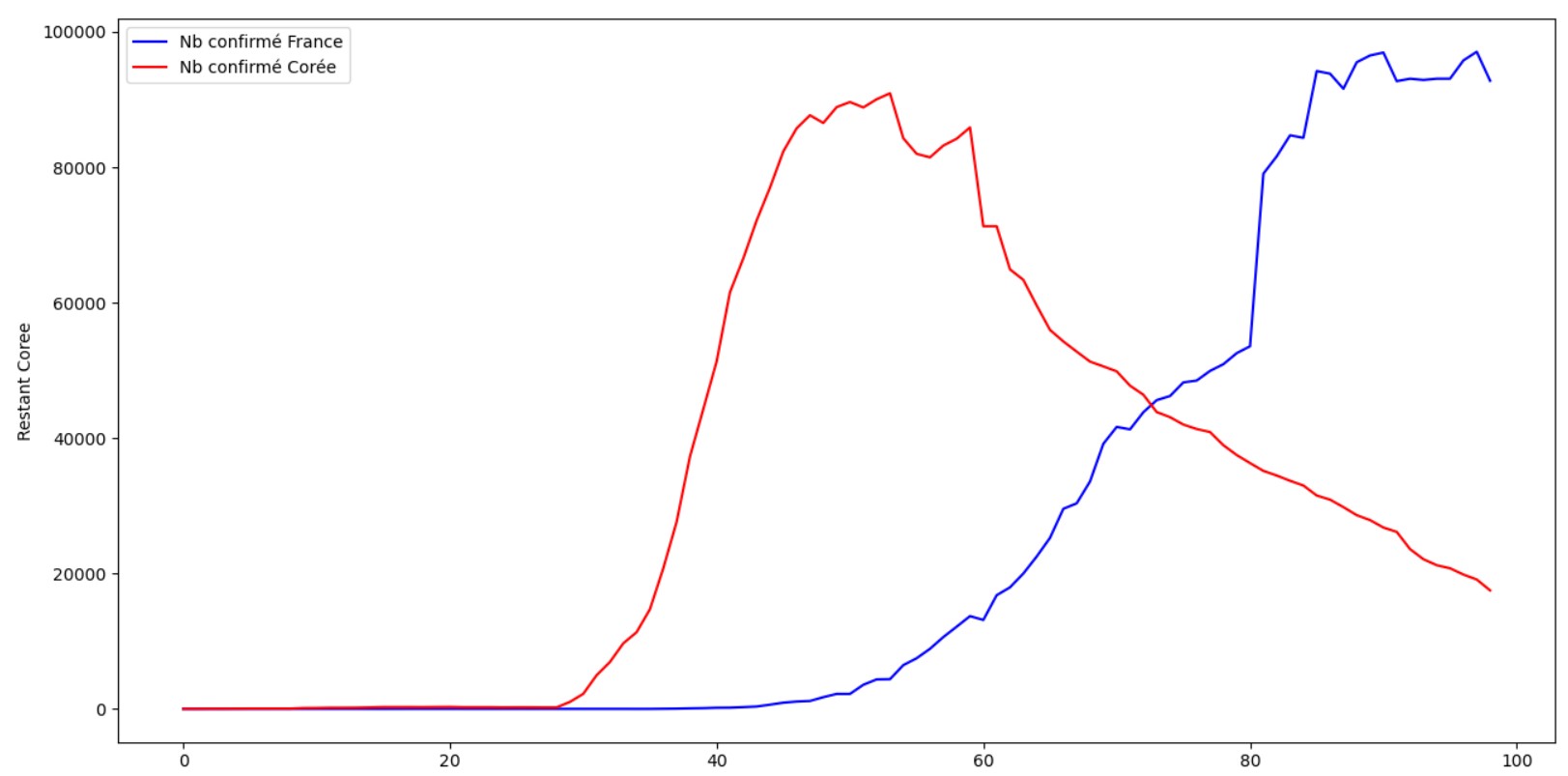
On voit donc bien le retournement de tendance de la Corée qu'il nous reste à amorcer en France pour ensuite attaquer une réelle baisse de l'épidémie.
Prédiction de Time Series
On voit qu'en 46 jours depuis le début de la baisse en Corée, celle-ci à diminuer de 65% son nombre de cas. Par ailleurs on voit qu'on obtient une tendance actuelle assez
linéaire. L'objectif va donc etre de récupérer le début de cette tendance baissière et d'appliquer un modèle de prédiction autant de fois que nécessaire pour arriver à 0 cas en Corée.
Pour cela nous allons utiliser le modèle ARIMA (Autoregressive Integrated Moving Average) qui mélange de l'Autorégression et les moyennes mobiles avec une phase de préprocessing
appelé Intégration.
# -*- coding: utf-8 -*-
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima_model import ARIMA
import warnings # `do not disturbe` mode
warnings.filterwarnings('ignore')
# Les DATA
fileconfirmed = "confirmed_global_29-04.csv"
filedeath = "deaths_global_29-04.csv"
filerecovered = "recovered_global_29-04.csv"
# Je repars du meme code precedent meme s'il pourrait etre allege
# On cree le Dataframe en recuperant la France et la Coree du Sud qui servira de comparaison
data = pd.read_csv(fileconfirmed)
data['Province/State'] = data['Province/State'].fillna(0)
dataconfirmed = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
data = pd.read_csv(filedeath)
data['Province/State'] = data['Province/State'].fillna(0)
datadeaths = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
data = pd.read_csv(filerecovered)
data['Province/State'] = data['Province/State'].fillna(0)
datarecovered = data[(((data['Country/Region'] == 'France') | (data['Country/Region'] == 'Korea, South')) & (
data['Province/State'] == 0))]
# Au vu du format de la Time Serie, on va transformer les colonnes en ligne
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
dataconfirmed = pd.np.transpose(dataconfirmed)
cols = dataconfirmed.columns
dataconfirmed = dataconfirmed.rename(columns={cols[0]: 'Confirmed France', cols[1]: 'Confirmed Coree'})
datadeaths = datadeaths.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datadeaths = pd.np.transpose(datadeaths)
cols = datadeaths.columns
datadeaths = datadeaths.rename(columns={cols[0]: 'Deaths France', cols[1]: 'Deaths Coree'})
datarecovered = datarecovered.drop(columns=['Province/State', 'Country/Region', 'Lat', 'Long'])
datarecovered = pd.np.transpose(datarecovered)
cols = datarecovered.columns
datarecovered = datarecovered.rename(columns={cols[0]: 'Recovered France', cols[1]: 'Recovered Coree'})
# On concatene les Dataframe pour n'en faire qu'un
datacomplete = pd.concat([dataconfirmed, datadeaths, datarecovered], axis=1, sort=False)
datacomplete['Restant France'] = datacomplete['Confirmed France'] - datacomplete['Recovered France'] - datacomplete[
'Deaths France']
datacomplete['Restant Coree'] = datacomplete['Confirmed Coree'] - datacomplete['Recovered Coree'] - datacomplete[
'Deaths Coree']
datacomplete = datacomplete.reset_index()
# La prediction Time Series prend une serie en entree, ici les donnees de la Coree.
data = datacomplete['Restant Coree']
data = data[66:]
# Nous allons faire une boucle qui va appeler le modele ARIMA pour faire une prediction, puis ajouter celle-ci et relancer la prediction 30fois pour avoir 30jours de prediction
for a in range(1,30):
model = ARIMA(data, order=(1, 1, 1))
model_fit = model.fit(disp=False)
yhat = model_fit.predict(len(data), len(data), typ='levels')
data = data.append(yhat)
# On affiche la prediction pour voir quand elle passe le 0
print(yhat)
plt.figure(figsize=(24, 10))
# On affiche le tout avec matplotlib cette fois
plt.plot(data.index, data, 'r-', label='Prediction')
plt.show()
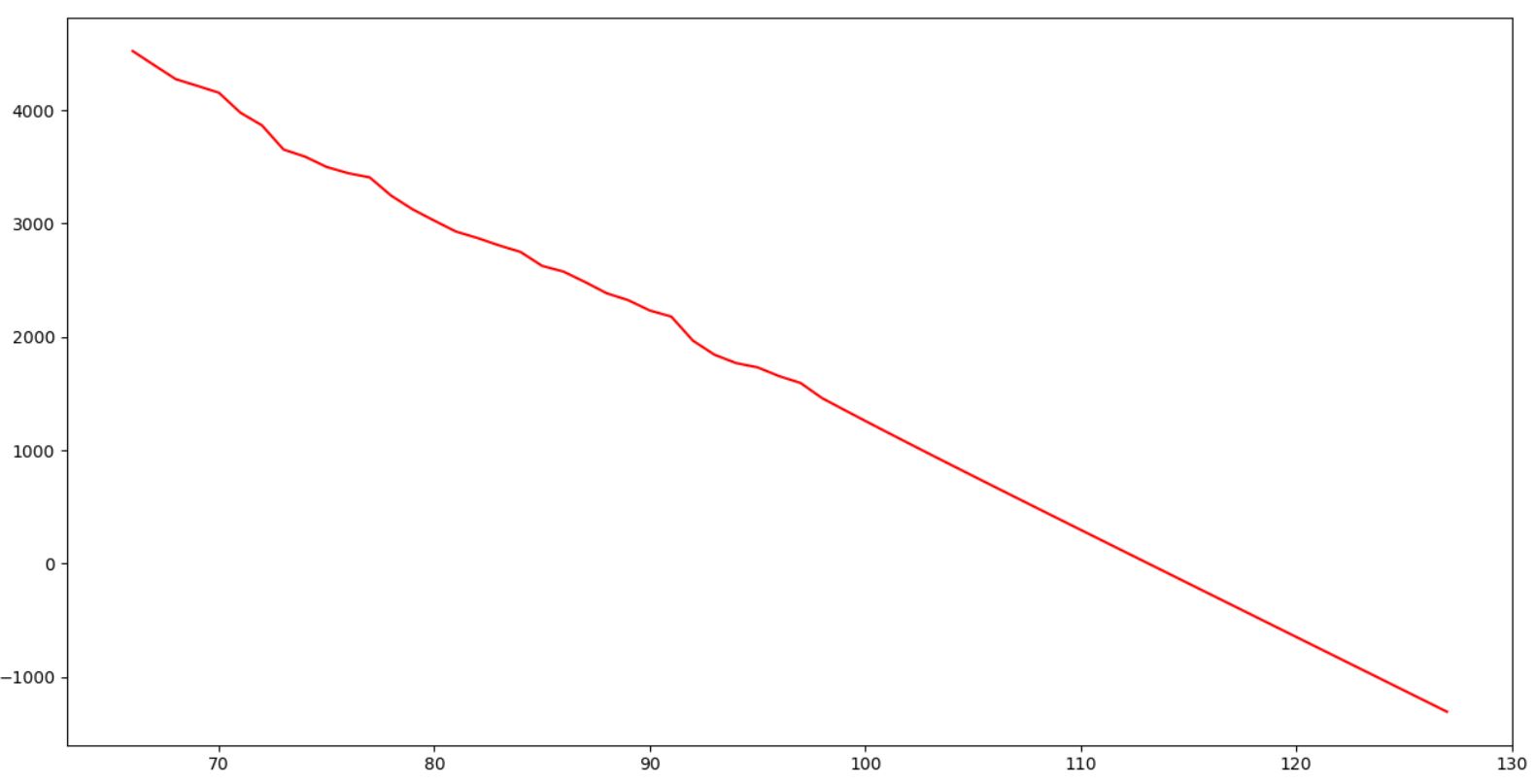
Et voilà, on obtient une droite de prédiction et on constate qu'elle passe les 0 au bout de 16 jours (voir dans les logs affichés par le print(yhat)). La cassure est survenue au 60e jour et nous en sommes au 98e jour.
Nous arrivons donc à une fin des cas de Covid-19 en Corée approximativement au bout de 54 jours après le retournement de tendance (autour du 18 Mai donc pour la Corée).
Nous pouvons donc espérer au mieux, à mon avis, si la rupture est effective au 11 mai, à une fin de crise Covid-19 en France au 04 Juillet.
Conclusion :
La modélisation est un élément très intéressant afin de constater ce que les chiffres présentent afin d'affirmer ou infirmer des hypothèses. La prédiction permet également
de se projeter mais rester sujette à énormément de facteurs externes qui la rende peu fiable dans le cas présent mais peut devenir très robuste dans des cas avec plus
d'information et des tendances saisonnières. Dans le cas présent, la méthode de traitement de la France est bien plus laxiste que celle de la Corée du Sud donc la date annoncée
me parait ultra optimiste mais l'avenir nous le dira :)
Have fun !
27-03-2020 16:06:41
Web Application COVID-19
Un petit post juste pour indiquer une petite appli que j'ai dev pour suivre statistiquement l'évolution du COVID dans le monde : http://covid.madpowah.org. J'essai de peaufiner cela donc ne vous étonnez pas de le voir évoluer.
Bon courage a tous pour le passage de cette crise.
08-12-2014 16:43:42
[Tool] ForensicPCAP, un outil d'analyse de PCAP en python
ForensicPCAP est disponible sur Github. Je vais l'améliorer pour ajouter des dumps automatiques d'images ou autres petites idées. Si vous avez un besoin particulier n'hésitez pas à m'en parler, je suis ouvert à toute proposition d'évolution.
Exemple :
user@puf:~$ ./forensicPCAP.py exemple.pcap ## Loading PCAP /home/user/exemple.pcap ... OK. ForPCAP >>> dns ## Listing all DNS requests ...OK. ## Result : 34 DNS request(s) ForPCAP >>> show 1 | blog.madpowah.org ForPCAP >>> mail ## Searching mail's request ... OK. ## Result : Mail's request : 0 ## Saving mails ... OK ForPCAP >>> web ## Searching web's request ... .................OK. Web's request : 17 ForPCAP >>> show GET / HTTP/1.1 Cache-Control: max-age = 4624 Connection: Keep-Alive Accept: */* If-Modified-Since: Sat, 22 Nov 2014 07:49:38 GMT ForPCAP >>> followtcpstream 50 ## Searching TCP Stream in PCAP ... OK ForPCAP >>> show 44 | Ether / IP / TCP 10.0.2.15:49163 > 10.0.2.100:http S 46 | Ether / IP / TCP 10.0.2.100:http > 10.0.2.15:49163 SA 47 | Ether / IP / TCP 10.0.2.15:49163 > 10.0.2.100:http A 50 | Ether / IP / TCP 10.0.2.15:49163 > 10.0.2.100:http PA / Raw 51 | Ether / IP / TCP 10.0.2.100:http > 10.0.2.15:49163 A 56 | Ether / IP / TCP 10.0.2.100:http > 10.0.2.15:49163 PA / Raw 62 | Ether / IP / TCP 10.0.2.15:49163 > 10.0.2.100:http PA / Raw 63 | Ether / IP / TCP 10.0.2.100:http > 10.0.2.15:49163 A 84 | Ether / IP / TCP 10.0.2.100:http > 10.0.2.15:49163 PA / Raw 94 | Ether / IP / TCP 10.0.2.15:49163 > 10.0.2.100:http A 159 | Ether / IP / TCP 10.0.2.15:49163 > 10.0.2.100:http PA / Raw 160 | Ether / IP / TCP 10.0.2.100:http > 10.0.2.15:49163 A 170 | Ether / IP / TCP 10.0.2.100:http > 10.0.2.15:49163 PA / Raw 174 | Ether / IP / TCP 10.0.2.15:49163 > 10.0.2.100:http A 195 | Ether / IP / TCP 10.0.2.15:49163 > 10.0.2.100:http RA ForPCAP >>> show raw GET / HTTP/1.1 Accept: */* If-Modified-Since: Mon, 24 Nov 2014 18:08:00 GMT If-None-Match: 1416852480000 A-IM: feed Accept-Language: en-US Accept-Encoding: gzip, deflateHave fun !
03-05-2014 21:40:01
[Secu] Blocage compte avec Pwpolicy sous MacOSX
Je test : OK ca marche sauf que ... le compte se débloque au bout d'1mn. Pas d'info sur le sujet dans le man. Rien non plus dans le guide sécu de Apple ... Super.
Bref au bout de quelques temps de recherche voici la commande pour configurer cette durée de déblocage (par exemple 90 mn) :
pwpolicy -n /Local/Default -setglobalpolicy "minutesUntilFailedLoginReset=90"Have fun.
09-10-2013 20:27:12
[Tuto] Probleme installation Cobradroid
1ère étape l'installation (sous Linux). Je suis donc la doc du site officiel et là ... c'est le drame. Impossible d'utiliser l'API Cobra lorsque je crée un AVD.
L'astuce est que contrairement à ce qui est indiqué il ne faut pas déposer les fichiers sous :
~/android-sdk-linux/addon-cobradroid-betamais sous :
~/android-sdk-linux/add-ons/addon-cobradroid-betaOn relance l'émulateur et on crée un AVD et la dans Target on peut bien maintenant choisir CobraDroid.
Après en théorie cela peut très pratique mais personnellement le gros problème que j'ai rencontré est qu'il n'intègre pas la Google API (utilisé par exemple par maps) et donc cela empèche l'installation de pas mal d'applis.
2e inconvénient est qu'il ne propose pour l'instant une version 2.3.7 (qu'il faut d'ailleurs penser à installer / mettre à jour avant d'utiliser CobraDroid) mais bon une mise à jour est dans les tuyaux donc cela sera à suivre !
Have fun !
09-10-2013 20:10:53
[Tuto] Changement de lecteur PDF avec Cuckoo
Par exemple pour l'ouverture d'un fichier PDF, si on souhaite évaluer un code sur un autre logiciel que Adobe Reader, il va falloir modifier un tout petit peu le code de Cuckoo. En effet mme si la VM est configurée par exemple pour ouvrir les PDF avec Foxit, Cuckoo ne le sachant pas va tenter de lancer l'analyse avec Adobe qui lui est configuré et afficher un message d'erreur.
Pour intégrer donc Foxit, rien de bien compliqué. Déjà on commence par l'installer dans la VM et à la cloner. Ensuite on va ouvrir le fichier cuckoo/analyzer/windows/modules/packages/pdf.py et ajouter le chemin d'installation de Foxit à la liste path comme cela :
paths = [
os.path.join(os.getenv("ProgramFiles"), "Adobe", "Reader
8.0", "Reader", "AcroRd32.exe"),
os.path.join(os.getenv("ProgramFiles"), "Adobe", "Reader
9.0", "Reader", "AcroRd32.exe"),
os.path.join(os.getenv("ProgramFiles"), "Adobe", "Reader
10.0", "Reader", "AcroRd32.exe"),
os.path.join(os.getenv("ProgramFiles"), "Adobe", "Reader
11.0", "Reader", "AcroRd32.exe"),
os.path.join(os.getenv("ProgramFiles"), "Foxit Software",
"Foxit Reader", "Foxit Reader.exe")
]
On relance Cuckoo et le tour est joué !
05-10-2013 00:27:06
[Bug] Correction bug Browse Cuckoo
IP - - [05/Oct/2013 02:18:30] "GET / HTTP/1.1" 200 161508
Traceback (most recent call last):
File "/usr/lib/python2.7/dist-packages/bottle.py", line 737, in _handle
return route.call(**args)
File "/usr/lib/python2.7/dist-packages/bottle.py", line 1504, in wrapper
rv = callback(*a, **ka)
File "/usr/lib/python2.7/dist-packages/bottle.py", line 1454, in wrapper
rv = callback(*a, **ka)
File "./cuckoo/utils/web.py", line 71, in browse
sample = db.view_sample(row.sample_id)
File "~/secu/cuckoo/utils/../lib/cuckoo/core/database.py", line 824, in view_sample
session.expunge(sample)
UnboundLocalError: local variable 'sample' referenced before assignment
Pour corriger cela, il faut ouvrir web.py et modifier la ligne
sample = db.view_sample(row.sample_id)par
sample = db.view_sample(row.id)Le serveur web redémarre automatiquement à l'enregistrement de la modif et le Browse marche niquel !
Have fun :)